[toc]
机器学习笔记1

机器学习介绍
机器学习(Machine Learning)是人工智能(AI)的一个分支,它使计算机系统能够利用数据和算法自动学习和改进其性能。最终让机器通过经验(数据)来做决策和预测。
机器学习是让计算机通过数据进行学习的一种技术,广泛应用于各行各业。
想象一下,你正在教一个小孩认识各种动物,你不需要告诉他"所有猫都有两只耳朵、四条腿、胡须…"这样复杂的规则,而是给他看很多猫的照片,告诉他"这是猫",慢慢地,这个小孩就能自己认出以前没见过的猫了。

简而言之,机器学习就是这样一种让计算机学习的方法:我们不直接编写复杂的规则,而是让计算机从大量数据中自动找出规律和模式。
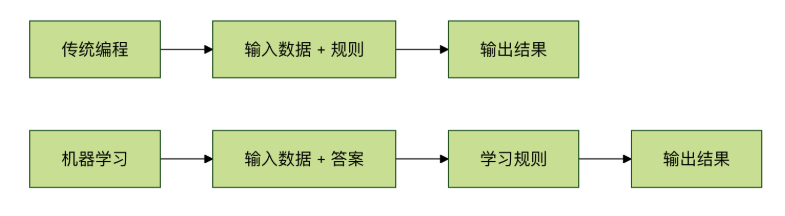
机器学习与传统编程的区别
| 传统编程 | 机器学习 |
|---|---|
| 程序员通过编写明确的规则,来实现各种功能 | 计算机从数据中学习规则,然后来实现各种功能 |
| 适用于问题明确、规则清晰的情况 | 适用于复杂、规则难以明确的情况 |
| 例子:编写计算器程序 | 例子:编写识别垃圾邮件的程序 |
机器学习的应用领域
- 推荐系统: 例如,抖音推荐你可能感兴趣的视频,淘宝推荐你可能会购买的商品等。
- 自然语言处理(NLP): 机器学习在语音识别、机器翻译、情感分析、聊天机器人等方面的应用。例如,Google 翻译、智能客服等。
- 计算机视觉: 机器学习在图像识别、物体检测、面部识别、自动驾驶等领域有广泛应用。例如,自动驾驶汽车通过摄像头和传感器识别周围的障碍物,识别行人和其他车辆。
- 金融分析: 机器学习在股市预测、信用评分、欺诈检测等金融领域具有重要应用。例如,银行利用机器学习检测信用卡交易中的欺诈行为。
- 医疗健康: 机器学习帮助医生诊断疾病、发现药物副作用、预测病情发展等。例如,帮助医生分析患者的病历数据,提供诊断和治疗建议。
- 游戏和娱乐: 机器学习不仅用于游戏中的智能对手,还应用于游戏设计、动态难度调整等方面。例如,AlphaGo 使用深度学习技术战胜了围棋世界冠军
机器学习的类型
机器学习主要分为以下三种类型。
监督学习(Supervised Learning)
- 定义: 监督学习是指使用带标签的数据进行训练,模型通过学习输入数据与标签之间的关系,来做出预测或分类。
- 应用: 分类(如垃圾邮件识别)、回归(如房价预测)。
- 例子: 线性回归、决策树、支持向量机(SVM)。
无监督学习(Unsupervised Learning)
- 定义: 无监督学习使用没有标签的数据,模型试图在数据中发现潜在的结构或模式。
- 应用: 聚类(如客户分群)、降维(如数据可视化)。
- 例子: K-means 聚类、主成分分析(PCA)。
强化学习(Reinforcement Learning)
- 定义: 强化学习通过与环境互动,智能体在试错中学习最佳策略,以最大化长期回报。每次行动后,系统会收到奖励或惩罚,来指导行为的改进。
- 应用: 游戏AI(如AlphaGo)、自动驾驶、机器人控制。
- 例子: Q-learning、深度Q网络(DQN)。
如图所示,是机器学习的三种类型。 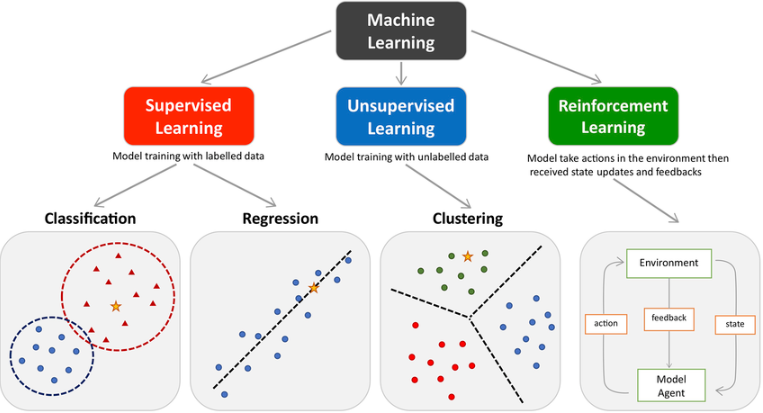
机器学习三大要素
① 数据: 数据是机器学习的燃料,质量越高、数量越多的数据,通常能让模型学得越好。
- 训练数据:用来教模型的数据
- 测试数据:用来检验模型学习效果的数据
- 真实数据:模型在实际应用中遇到的新数据
② 算法:算法是机器学习的学习方法,不同的算法适用于不同类型的问题。
- 监督学习算法:有标准答案的学习
- 无监督学习算法:没有标准答案,自己找规律
- 强化学习算法:通过试错和奖励来学习
③ 模型:模型是学习的结果,就像学生学到的知识一样。
- 训练过程:算法从数据中学习规律
- 推理过程:使用学到的规律做预测
机器学习的基本术语
机器学习有以下基本术语,假设我们要训练一个机器人来识别不同的水果。
- 数据(Data):各种水果的图片和信息
- 特征(Features):水果的颜色、形状、大小、味道
- 标签(Labels):这个水果叫什么名字(苹果、香蕉、橙子)
- 模型(Model):机器人学到的"识别水果的方法"
- 训练(Training):教机器人认识水果的过程
- 推理(Inference):机器人识别新水果的能力
数据(Data)
数据是机器学习的"原材料",就像厨师做菜需要的食材一样。没有数据,机器学习就无法进行。
数据的类型
机器学习使用的数据,主要分为结构化数据和非结构化数据。
- 结构化数据:就是有明确的结构,比如表格数据,每个数据都有固定的字段,就像数据库中的表格一样。
- 非结构化数据:没有固定的结构,比如文本、图像、视频等。
特征(Features)
特征是数据的"可观察属性"。就像描述一个人的特征:身高、体重、发色、性格等。
特征选择是一个重要的步骤,需要根据数据的特性和问题的性质来选择。一个好特征是能够帮助模型准确预测标签的特征。
特征的类型
特征可以用多种数据类型来表示。如数值特征,类别特征,文本特征,图像特征等。
# 数值特征示例
numerical_features = {
'年龄': [25, 30, 35, 40],
'收入': [5000, 8000, 12000, 15000],
'身高': [165, 170, 175, 180]
}
# 类别特征示例
categorical_features = {
'性别': ['男', '女', '男', '女'],
'学历': ['本科', '硕士', '博士', '本科'],
'城市': ['北京', '上海', '广州', '深圳']
}
# 文本特征示例
text_features = {
'评论': [
'这个产品很好用,推荐购买!',
'质量一般,不太满意。',
'性价比高,值得入手。'
]
}标签(Labels)
标签是我们想要预测的"答案",就像考试题的正确答案一样。在监督学习中,每个数据样本都有一个对应的标签。
标签的类型
标签也可以是数值型或类别型。
- 数值型标签:如房价、股票价格等连续的数值。
- 类别型标签:如垃圾邮件、非垃圾邮件、情感分析中的正面、负面等。
# 分类标签示例
classification_labels = {
'邮件类型': ['垃圾邮件', '正常邮件', '垃圾邮件', '正常邮件'],
'情感倾向': ['正面', '负面', '中性', '正面'],
'疾病诊断': ['患病', '健康', '健康', '患病']
}
# 数值标签示例
regression_labels = {
'房价': [250000, 320000, 180000, 450000],
'温度': [25.5, 28.3, 22.1, 30.0],
'股票价格': [100.5, 105.2, 98.7, 110.3]
}模型(Model)
模型是机器学习算法从数据中学到的"规律"或"模式",就像学生从课本中学到的知识一样。
模型本质上可以是一个数学函数,用户通过输入特征来预测标签。
训练(Training)
训练是模型学习的过程,就像学生上课学习知识一样。在训练过程中,模型不断调整参数,使预测结果越来越接近真实标签。
训练的流程如图所示 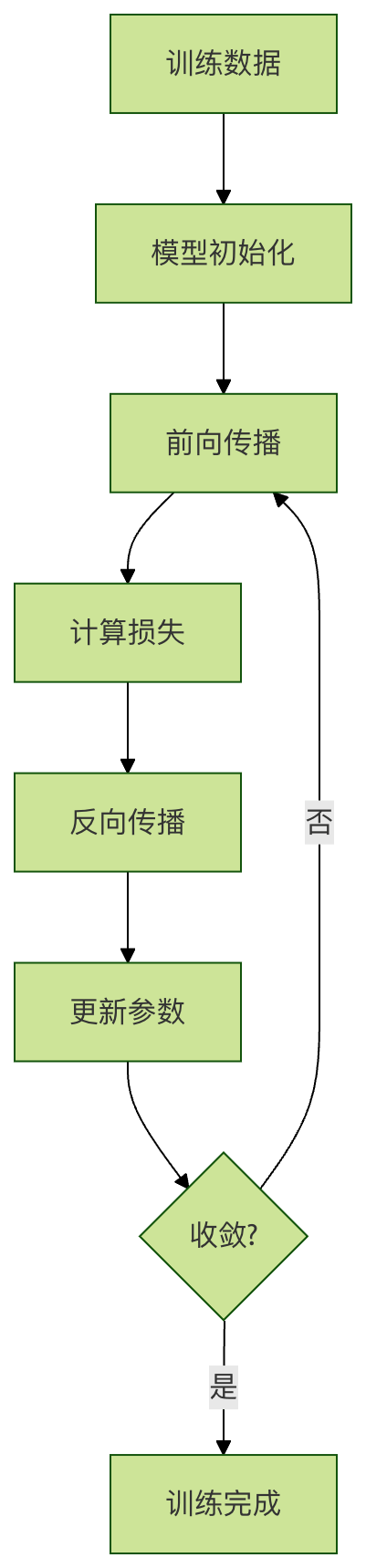
推理
推理是使用训练好的模型进行预测的过程,就像学生用学到的知识解答考试题一样。
机器学习是如何工作的?
机器学习的大致流程
机器学习通过让计算机从大量数据中学习模式和规律来做出决策和预测。
- 首先,收集并准备数据,然后选择一个合适的算法来训练模型。
- 然后,模型通过不断优化参数,最小化预测错误,直到能准确地对新数据进行预测。
- 最后,模型部署到实际应用中,实时做出预测或决策,并根据新的数据进行更新模型,从而不断提高模型的性能。
机器学习的详细流程
① 数据收集
- 收集数据:这是机器学习的第一步,涉及收集相关数据。数据可以来自数据库、文件、网络或实时数据流。
- 数据类型:可以是结构化数据(如表格数据)或非结构化数据(如文本、图像、视频)。
② 数据预处理
- 清洗数据:处理缺失值、异常值、错误和重复数据。
- 特征工程:选择有助于模型学习的最相关特征,可能包括创建新特征或转换现有特征。
- 数据标准化:调整数据的尺度,使其在同一范围内,有助于某些算法的性能。
③ 选择模型
- 确定问题类型:根据问题的性质(分类、回归、聚类等)选择合适的机器学习模型。
- 选择算法:基于问题类型和数据特性,选择一个或多个算法进行实验。
④ 训练模型
- 划分数据集:将数据分为训练集、验证集和测试集。
- 训练:使用训练集上的数据来训练模型,调整模型参数以提高模型的性能。
- 验证:使用验证集来调整模型参数,防止过拟合。
⑤ 评估模型
- 性能指标:使用测试集来评估模型的性能,常用的指标包括准确率、召回率、F1分数等。
- 交叉验证:一种评估模型泛化能力的技术,通过将数据分成多个子集进行训练和验证。
⑥ 模型优化
- 调整超参数:超参数是学习过程之前设置的参数,如学习率、树的深度等,可以通过网格搜索、随机搜索或贝叶斯优化等方法来调整。
- 特征选择:可能需要重新评估和选择特征,以提高模型性能。
⑦ 部署模型
- 集成到应用:将训练好的模型集成到实际应用中,如网站、移动应用或软件中。
- 监控和维护:持续监控模型的性能,并根据新数据更新模型。
⑧ 反馈循环
- 持续学习:机器学习模型可以设计为随着时间的推移自动从新数据中学习,以适应变化。