[toc]
Flink笔记1
当前使用Flink版本为: Flink-1.17.2
先暂停,感觉大数据目前用不上,后续再学。。。。。
Flink介绍
Apache Flink官网 https://flink.apache.org/
Apache Flink 是一个开源的分布式数据处理框架,旨在处理实时数据流和批处理数据。它提供了高性能、高吞吐量的数据流处理引擎,允许开发者编写复杂的流处理应用程序,处理来自多种数据源的数据流。
Flink的应用场景
- 电商和市场营销:实时数据报表,实时推荐。
- 物联网(IOT):传感器的实时数据采集,实时交通运输等。
- 物流服务业:订单实时更新,信息实时推送。
- 金融业:业务实时结算,业务实时监测。
如图所示,各种各样的数据经过Flink计算处理之后,可以传输给应用,日志,数据库等。 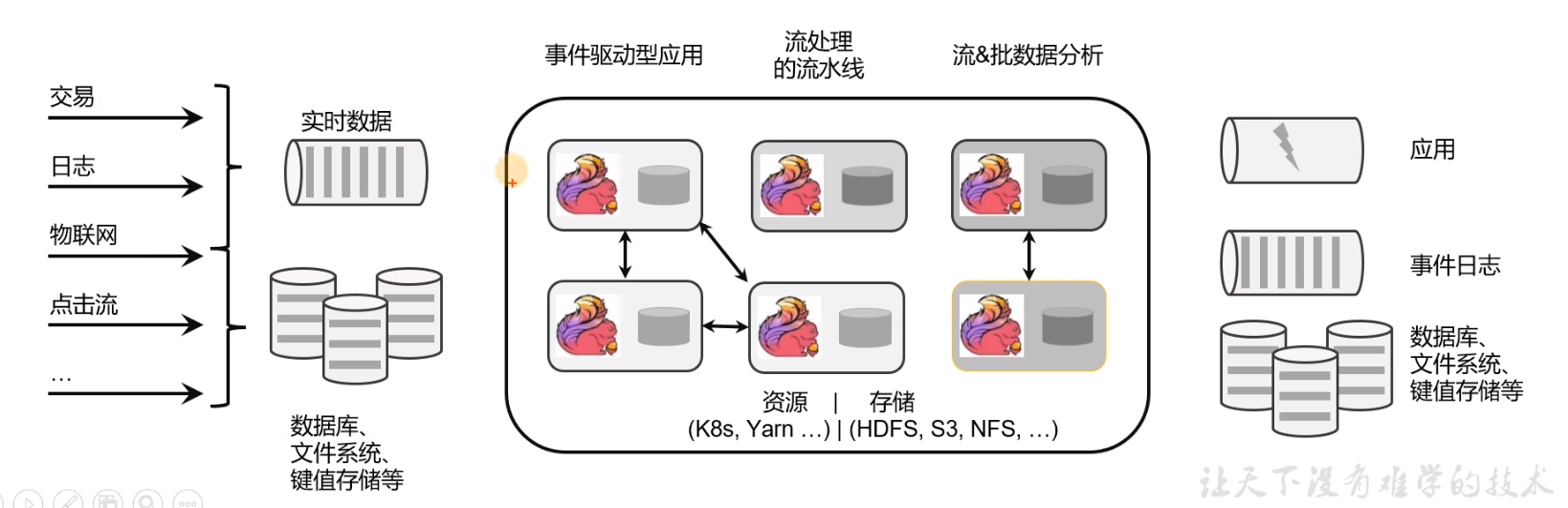
Flink的主要特点和特性如下
- 流处理模型: 支持事件驱动的流处理模型,能够处理无界和有界的数据流,并提供了精确的事件时间处理机制。
- 状态管理: 内置支持状态管理,允许在流处理应用中有效地管理和访问状态,以实现更复杂的业务逻辑。
- 容错性: 具备高度的容错性,通过检查点(checkpoint)机制和分布式快照(snapshot)技术,能够在节点故障时保证数据不丢失并恢复到一致状态。
- 可扩展性: 可以水平扩展以处理大规模数据集和高并发的数据处理任务,支持在集群中动态分配和调度任务。
- 与其他系统集成: 支持各种存储系统(如 Kafka、Hadoop HDFS)、消息队列系统(如 RabbitMQ)、数据仓库(如 Hive)、以及其他计算框架(如 Apache Spark)无缝集成,使其成为现代大数据处理生态系统中的一个重要组成部分。
总之,Apache Flink 是一个强大而灵活的数据流处理框架,用于实时数据流处理和批处理任务,广泛应用于大数据分析、实时数据仓库、监控和警报、实时推荐等领域。
什么是有界数据流和无界数据流?
无界数据流:是指该数据流只有开始,没有结束。即无界数据流会无休止的产生数据。因此无界数据流的数据需要长期持续处理。
有界数据流:是指该数据库有开始,有结束。即有界数据流可以在获取到所有数据之后再进行计算处理。因此有界数据流处理也被称为批量数据处理。
Flink 和 SparkStreaming 的区别
- 处理模型上:Flink采用的是基于事件时间的处理模型。Spark Streaming使用的是微批处理模型。
- 状态管理:Flink 提供了内置的状态管理机制,支持在流处理过程中有效管理和访问状态。Spark Streaming 不提供状态管理机制。
- 延迟和吞吐量: Flink 通常能够实现更低的处理延迟。Spark Streaming 的微批处理模型会导致一定的批处理延迟。
- 容错性: Flink 使用分布式快照技术来实现高效的容错性。Spark Streaming 通过 Spark 的 RDD lineage 来实现容错性。
Flink的两个重要概念:JobManager 和 TaskManager
JobManager(作业管理器)
在 Apache Flink 中,JobManager 是 Flink 的主要协调节点和控制中心。它负责管理和调度整个作业的执行过程。
JobManager 的主要职责包括:
- 作业管理与调度:
- 接收来自客户端的作业提交请求,并将作业转化为作业图(JobGraph)。
- 将作业图分解为任务(Tasks)并分配给集群中的 TaskManager 执行。
- 协调任务的执行顺序和并行度,确保作业能够按照预期的流程执行。
- 故障恢复:
- 监控整个作业的执行状态和 TaskManager 的健康状况。
- 在 TaskManager 失效或者任务执行失败时,负责重新调度任务实例以保证作业的完成。
- 资源管理:
- 与资源管理器(如 YARN、Kubernetes 或者自带的 Standalone 部署)进行交互,以获取运行作业所需的计算资源(CPU、内存等)。
- 动态地管理集群中 TaskManager 的数量和资源配置,以适应作业的需求变化。
总之,JobManager 在 Flink 中是非常重要的组件,它负责管理整个作业的生命周期,保证作业能够高效、可靠地在Flink集群中运行并完成。
TaskManager(任务管理器)
在 Apache Flink 中,TaskManager 是执行作业任务的工作组件。TaskManager 负责实际执行作业中定义的各个任务(Tasks)。
TaskManager 的主要职责包括:
- 任务执行: 接收来自 JobManager 的任务部署描述,并根据描述实例化并执行具体的任务。
- 状态管理:负责管理和维护任务执行过程中的状态。包括任务运行时的数据状态和状态变化等。
- 数据交换与通信:处理与其他 TaskManager 之间的数据交换和通信。
- 资源管理:管理 TaskManager 节点上的计算资源,包括 CPU、内存等资源的分配和利用。
在一个 Flink 集群中,通常会有多个 TaskManager 节点组成,每个 TaskManager 可以同时执行一个或多个任务,具体取决于作业的并行度设置和资源配置。并且 TaskManager 负责从输入源接收数据、执行数据转换操作(如 map、reduce 等)、并将结果输出到外部系统或下游任务。
通过多个 TaskManager 的协同工作,Flink 能够实现高吞吐量和低延迟的流处理能力。
如图所示,Flink内部的工作流程如下。 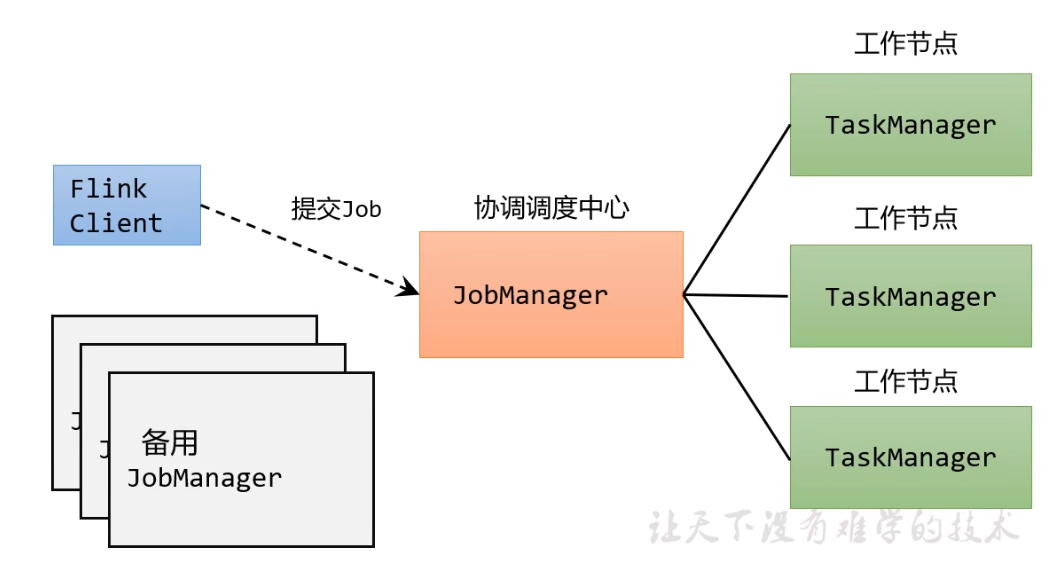
Flink集群的架构
当我们安装部署多个Flink,组成Flink集群的时候。需要遵循一主多从的架构方式。即一个Flink节点作为 JobManager 主节点,其他Flink节点作为 TaskManager 从节点。
Flink集群的运行模式
集群的运行模式是指,在不同的场景下集群资源的使用和分配方式,会有所区别。
Flink集群主要有以下三种运行模式:会话模式(session mode), 单作业模式(per-job mode), 应用模式(application mode)。
会话模式(session mode)
会话模式是指:集群启动时所有资源都已经确定,集群中的作业会互相竞争集群中的资源。
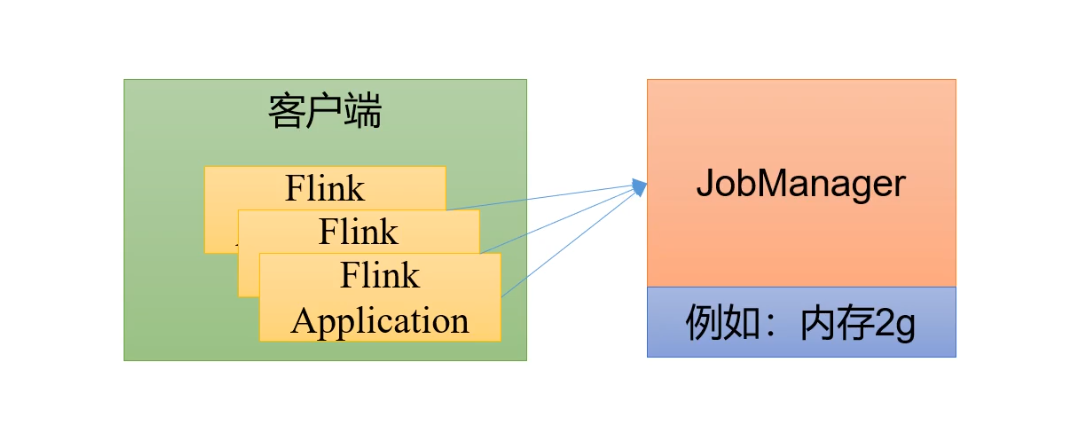
会话模式中的集群资源已经固定下来。因此会话模式适合小规模,执行时间短的大量作业。
单作业模式(per-job mode)
单作业模式:提交到Flink集群中的每个作业job都独立运行。每个作业有自己独立的资源调度和状态管理。
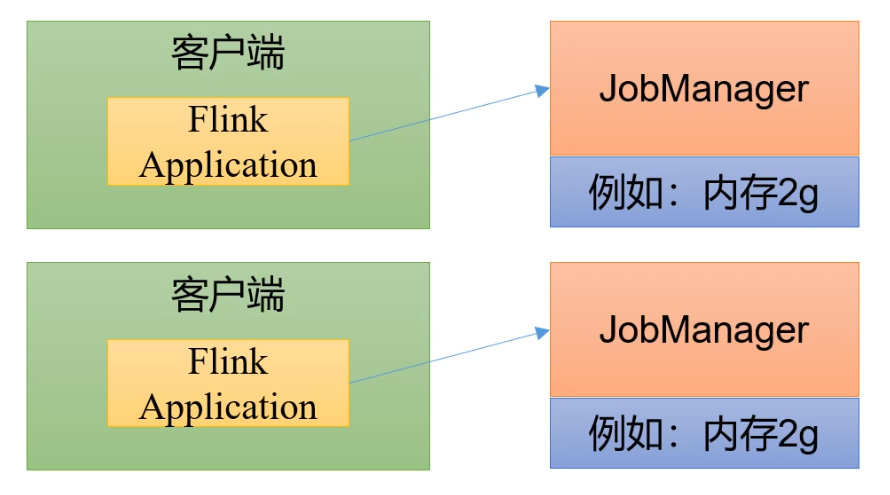
Flink的单作业模式,需要依赖一些资源管理框架才能运行。例如Hadoop Yarn , K8S等。
应用模式
应用模式是指:不使用客户端。直接把应用提交到JobManager中运行。一个JobManager运行一个应用。应用结束后,JobManager就关闭了。
Flink的API分层设计
如图所示是Flink的API分层设计
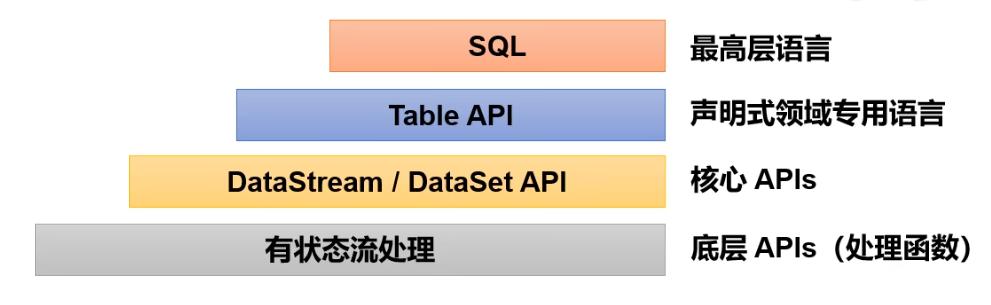
- 状态流处理API:该API对最原始的状态流进行加工处理。提供了底层函数。
- DataStream API (流处理) 和 DataSet API(批处理):封装了底层的处理函数,提供通用模块。例如map,faltmap,joins,windows等算子。
- Table API: 以表为中心的api,可以把数据转换为表,也提供了操作表的方法。例如 select,join,group-by等。
- SQL:可通过SQL表达式的方式。实现各种对数据的操作。
Flink集群的部署模式
部署模式是指在不同的应用场景下,Flink集群有不同的安装部署的方式。
Standalone 模式
Standalone 模式是指独立运行Flink集群,不依赖任何外部资源管理平台。缺点是无法自动扩展资源,必须手动扩展资源。
Standalone 模式一般在开发或测试场景下使用。
YARN 模式
客户端把Flink的应用程序提交给Hadoop Yarn 的 ResourceManager。ResourceManager会向 Yarn的NodeManager 申请容器。在这些容器上,Flink会部署JobManager和TaskManager实例节点,并且启动Flink集群。Flink会根据运行在JobManager上的作业,动态分配TaskManager的资源。
K8S模式
暂无
Flink的作业提交流程
如图所示,是Flink 在 Standalone 模式下的作业提交流程图 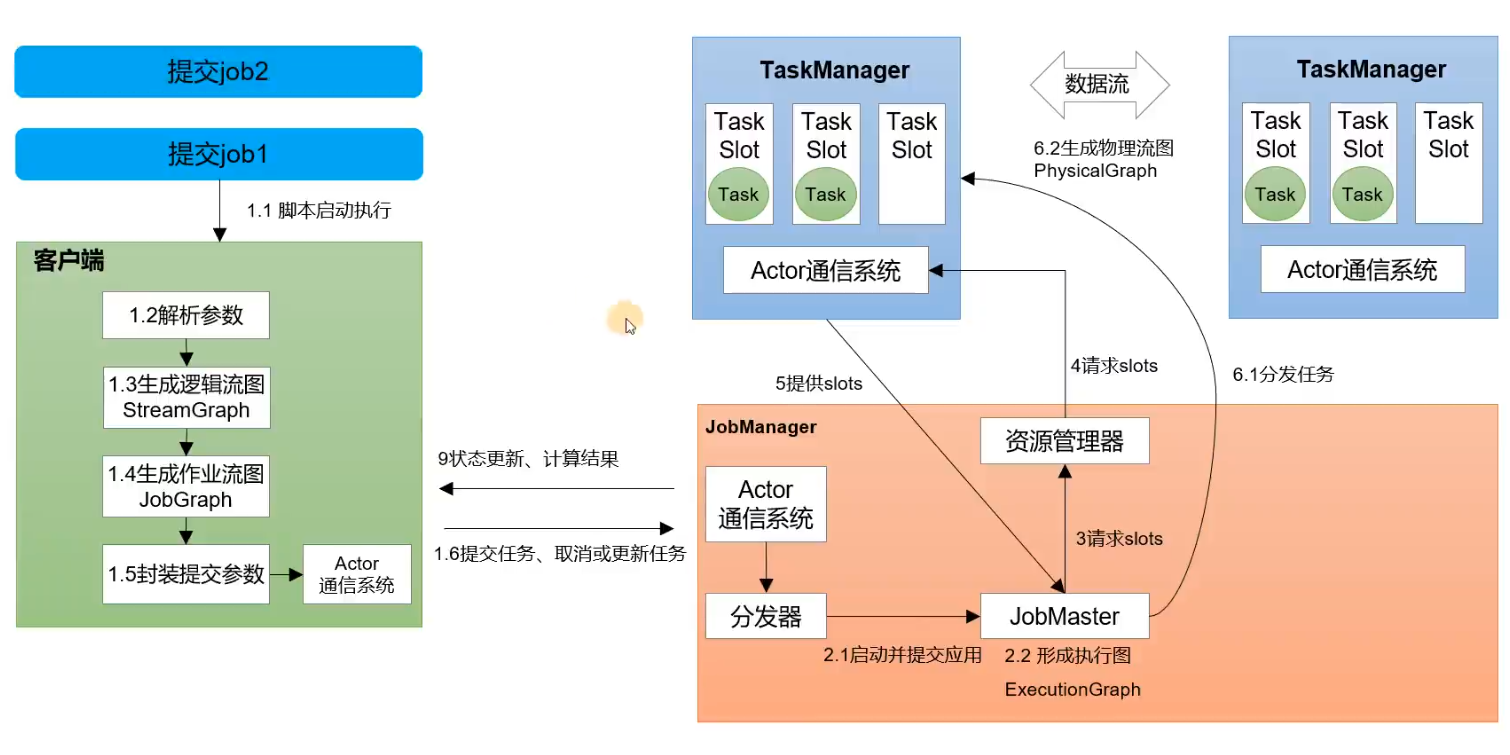
JobManager 作业管理器
JobManager 是Flink集群中的任务管理和调度的核心,是执行的主进程。JobManager包含三个子组件。
- jobMaster: 负责单独处理作业job。即每个job有自己对应的jobMaster
- 资源管理器:负责Flink集群中的资源分配和管理,在Flink集群中只有一个。
- 分发器:主要负责提供接口给客户端进行调用。并且为每一个新提交的作业job 启动一个新的jobMaster。
TaskManager 任务管理器
TaskManager是Flink中的工作进程,具体的计算工作是它来做的。每一个TaskManager都包含了一定数量的任务槽(task slot)。
Flink的核心概念
并行度
如果处理的数据量很大,我们可以把一个算子,复制到多个节点上。并把数据分配到各个节点上的算子中执行。这样一来相当于把一个算子拆分为多个并行的算子,从而实现并行计算。
一个算子(方法)的拆分个数,称之为并行度。
算子链
一个数据流在算子之间传输数据的方式,可以是一对一的直通模式,也可以是打乱之后的重分区模式。
任务槽(Task Slot)
Flink中的每一个TaskManager 都是一个JVM进程。它可以启动多个独立的线程,来并行执行多个子任务。
为了控制TaskManager并行执行任务的数量,我们需要在TaskManager上对每个任务运行时所占用的资源做出了划分。即任务槽。
每个任务槽 就是 TaskManager 上的资源的一个固定大小的小资源。这个小资源用来独立执行一个子任务的。
Flink的安装和部署
此处部署三个Flink节点,其中一个主节点,两个从节点。
| 节点容器 | 负责的组件 |
|---|---|
| myflink01 容器 | JobManager管理组件 |
| myflink02 容器 | TaskManager工作组件 |
| myflink03 容器 | TaskManager工作组件 |
按顺序执行下面的docker命令
# 下载flink镜像,该镜像包含flink 1.17.2 ,scala 2.12 和 jdk11
docker pull flink:1.17.2-scala_2.12-java11
# 创建flink网络,flink的各个节点都连接用一个网络
docker network create my-flink-net
# 部署 myflink01 容器
docker run -itd --name=myflink01 --network my-flink-net -p 38081:8081 --env FLINK_PROPERTIES="jobmanager.rpc.address: myflink01" flink:1.17.2-scala_2.12-java11 jobmanager
# 部署 myflink02 容器
docker run -itd --name=myflink02 --network my-flink-net --env FLINK_PROPERTIES="jobmanager.rpc.address: myflink01" flink:1.17.2-scala_2.12-java11 taskmanager
# 部署 myflink03 容器
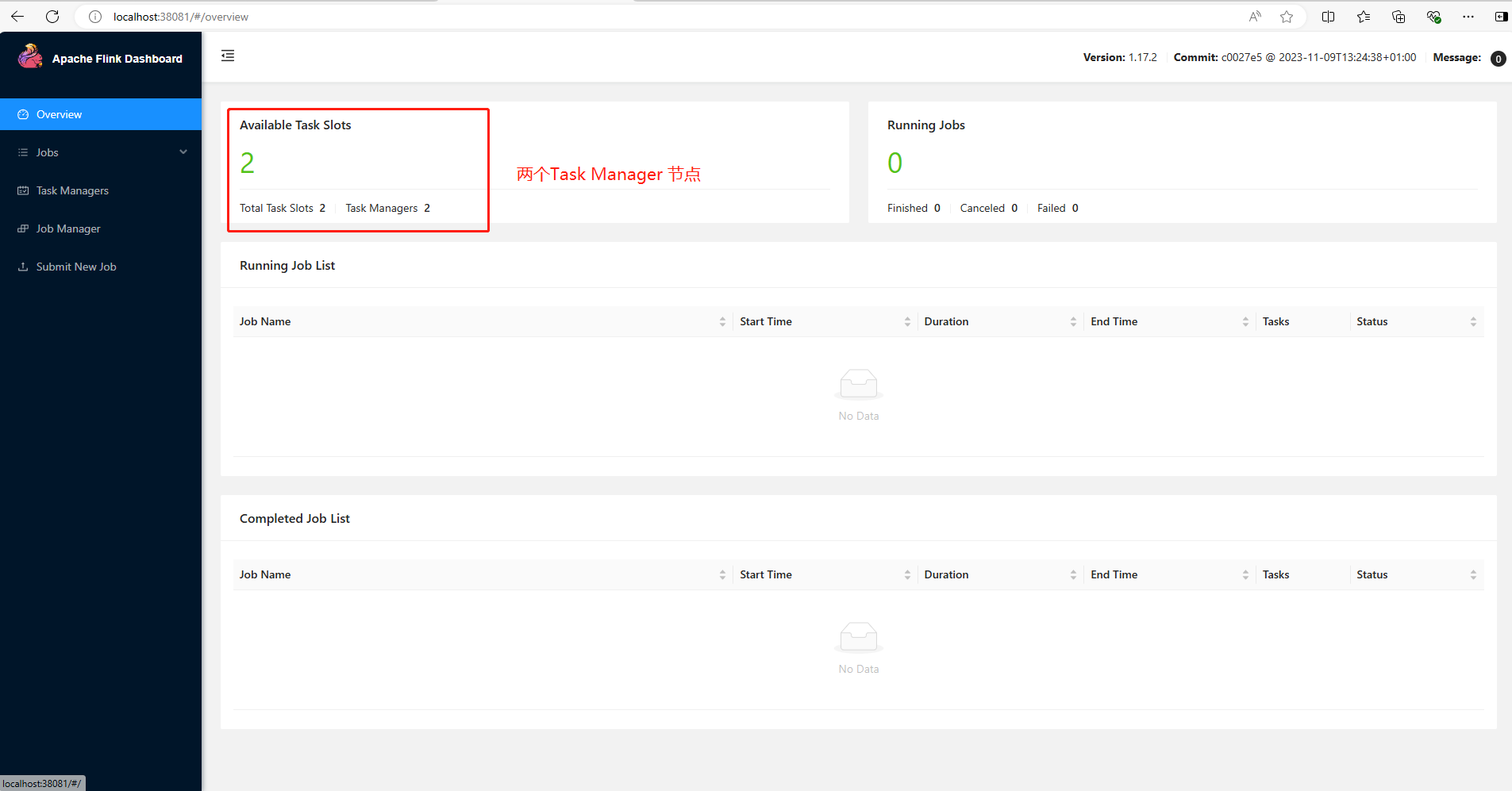
docker run -itd --name=myflink03 --network my-flink-net --env FLINK_PROPERTIES="jobmanager.rpc.address: myflink01" flink:1.17.2-scala_2.12-java11 taskmanagerFlink集群部署成功后,浏览器访问http://localhost:38081,可以看到myflink01 容器的UI管理界面。
配置文件
我们需要修改配置文件中的配置。
flink的配置文件是容器中的 /opt/flink/conf/flink-conf.yaml
flink-conf.yaml配置解释
# jobmanager进程内存大小配置,默认为1600M
jobmanager.memory.process.size: 1600m
# taskmanager进程内存大小配置,默认为1728M
taskmanager.memory.process.size: 1728m
# taskmanager进程能分配的slot数量设置,默认为1。 slot是指taskmanager中具体运行一个任务需要分配的计算资源。
taskmanager.numberOfTaskSlots: 1
# 任务执行的并行度,默认为1
parallelism.default: 1myflink01 容器
flink-conf.yaml文件
# jobmanager节点地址
jobmanager.rpc.address: myflink01
# 0.0.0.0 表示都可以访问,无限制
jobmanager.bind-host: 0.0.0.0修改workers文件,把TaskManager工作组件的容器名称填写进去
myflink02
myflink03修改master文件,把JobManager管理组件的容器名称填写进去
myflink01:8081DataStream API
DataStream API 是 Flink 的核心层API。一个Flink应用程序,其实就是使用 DataStream API 对数据的各种转换处理。
具体来说,Flink的应用程序的代码,主要包括以下几个步骤:
- 获取执行环境。
- 读取数据源。
- 进行数据处理(调用DataStream API对数据进行转换,处理)。
- 输出计算结果。
- 开始触发执行。
执行环境相关API
getExecutionEnvironment()方法
getExecutionEnvironment()方法会根据当前运行的上下文环境,来返回出当前运行环境。
如果程序是独立运行,则返回本地执行环境。如果是创建了jar包后运行,则返回集群的执行环境。
public class flink01 {
public static void main(String[] args) throws Exception {
//创建运行环境
//getExecutionEnvironment() 方法会自动识别是本地环境还是远程集群环境。都是默认配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
}
}createLocalEnvironment() 方法
该方法返回一个本地执行环境,可传入参数,参数是并行度。默认并行度为本地环境的CPU核心数。
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();createRemoteEnvironment() 方法
该方法返回一个集群执行环境。调用时指定JobManager的ip和端口号,以及在集群中执行jar包。
StreamExecutionEnvironment env = StreamExecutionEnvironment.createRemoteEnvironment("host",IP,"jar包路径");excute()方法
当调用执行环境的excute()方法后,会触发程序的执行。当时程序只有等到数据到来的时候,才会触发真正的计算,因此可以被成为懒执行。
public class flink01 {
public static void main(String[] args) throws Exception {
//创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//。。。。。。中间过程省略
//开始触发执行程序
env.execute();
}
}数据源相关API
Flink可以从各种数据源中获取数据,然后构建为DataStream。
fromCollection()方法:从集合中获取数据
代码如下
public class flink01 {
public static void main(String[] args) throws Exception {
//创建流处理运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//从集合创建流处理数据流
List<Tuple2<String, Integer>> data = new ArrayList<>();
data.add(new Tuple2<>("a", 1));
data.add(new Tuple2<>("b", 2));
data.add(new Tuple2<>("c", 3));
DataStreamSource<Tuple2<String, Integer>> dstream = env.fromCollection(data);
//打印流处理数据流
dstream.print();
//开始触发执行
env.execute();
}
}
//运行结果, 9>,8>,10> 是指 CPU的核心
// 9> (b,2)
// 8> (a,1)
// 10> (c,3)readTextFile()方法:从文件中获取数据
DataStreamSource<String> ds = env.readTextFile("C:\\Users\\18271\\Desktop\\words.txt");socketTextStream()方法:从socket流中获取数据
DataStreamSource<String> ds =env.socketTextStream("localhost",8080);数据处理 API (转换算子和聚合算子)
从数据源获取数据后,我们可以使用各种转换算子,将一个或多个 DataStream 转换为新的 DataStream
映射方法 map(func)
map方法会对DataStream中的元素,依次调用函数进行一一处理。
public class flink01 {
public static void main(String[] args) throws Exception {
//创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//把集合数据转换为DataStream
DataStreamSource<Integer> ds = env.fromCollection(Arrays.asList(1, 2, 3, 4));
//对 DataStream 调用 map方法进行转换
SingleOutputStreamOperator<Integer> mapDs = ds.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) throws Exception {
//把处理数据乘以10并返回
System.out.println("处理数据为 = "+value+",将其乘以10,并返回。");
return value*10;
}
});
//输出结果
mapDs.print();
//开始触发执行
env.execute();
}
}
//运行结果
// 处理数据为 = 1,将其乘以10,并返回。
// 处理数据为 = 4,将其乘以10,并返回。
// 17> 10
// 20> 40
// 处理数据为 = 3,将其乘以10,并返回。
// 处理数据为 = 2,将其乘以10,并返回。
// 19> 30
// 18> 20过滤方法 filter(func)
根据给定的函数 func 对 DataStream 进行过滤,返回一个包含符合条件元素的新 DataStream。如果满足过滤条件(返回true或1)则数据保留。不满足(返回false或0)则数据清除。
public class flink01 {
public static void main(String[] args) throws Exception {
//创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//把集合数据转换为DataStream
DataStreamSource<Integer> ds = env.fromCollection(Arrays.asList(1, 2, 3, 4));
//对 DataStream 调用 filter 方法进行转换
SingleOutputStreamOperator<Integer> filterDS = ds.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
//偶数返回true,奇数返回false
return value % 2 == 0 ? true: false;
}
});
//输出结果
filterDS.print("偶数流");
//对 DataStream 调用 filter 方法进行转换
SingleOutputStreamOperator<Integer> filterDS2 = ds.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
//偶数返回true,奇数返回false
return value % 2 == 0 ? false: true;
}
});
//输出结果
filterDS2.print("奇数流");
//开始触发执行
env.execute();
}
}
//运行结果
// 偶数流:10> 4
// 偶数流:8> 2
// 奇数流:16> 1
// 奇数流:18> 3扁平映射方法 flatMap()
flat是扁平化的意思。flatMap方法是将 DataStream 中的数据进行扁平化处理。 例如 DataStream 中的数据是集合,则扁平化是将集合中的数据拆分为一个个单独使用。
public class flink01 {
public static void main(String[] args) throws Exception {
//创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//多个集合转换为DataStream
DataStreamSource<List<Integer>> listDS = env.fromCollection(Arrays.asList(Arrays.asList(1, 2), Arrays.asList(3, 4)));
//调用 flatMap 方法进行转换
SingleOutputStreamOperator<Integer> outDS = listDS.flatMap(new FlatMapFunction<List<Integer>, Integer>() {
@Override
public void flatMap(List<Integer> value, Collector<Integer> out) throws Exception {
Integer next = value.iterator().next();
out.collect(next);
}
});
//输出结果
outDS.print();
//开始触发执行
env.execute();
}
}
//运行结果
// 5> 3
// 4> 1按键分区方法 keyBy()
在Flink中 DataStream 是没有直接进行聚合的API的。因此要做聚合,需要先对DataStream中的数据进行分区分组处理。
keyBy()方法通过指定key,把DataStream中数据进行分区。
public class flink01 {
public static void main(String[] args) throws Exception {
//创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//把集合数据转换为DataStream
DataStreamSource<Integer> ds = env.fromCollection(Arrays.asList(1, 2, 3, 4));
//对 DataStream 调用 keyBy 方法进行分组处理
KeyedStream<Integer, String> keyDS = ds.keyBy(new KeySelector<Integer, String>() {
@Override
public String getKey(Integer value) throws Exception {
//将偶数分为A组,奇数分为B组
return value % 2 == 0 ? "A组" : "B组";
}
});
//输出结果
keyDS.print();
//开始触发执行
env.execute();
}
}
//运行结果
// 3> 2
// 5> 1
// 3> 4
// 5> 3简单聚合方法 sum(),min(),max(),minBy() 等
这些简单聚合方法,都是需要通过KeyedStream对象进行调用。
//对 DataStream 调用 keyBy 方法进行分组处理,获取KeyedStream对象
KeyedStream<Integer, String> keyDS = ds.keyBy(.....);
SingleOutputStreamOperator<Integer> sum = keyDS.sum(0);
SingleOutputStreamOperator<Integer> max = keyDS.max(0);归约聚合方法 reduce()
把DataStream中的数据,按照指定函数进行两两聚合处理。
//对 DataStream 调用 keyBy 方法进行分组处理,获取KeyedStream对象
KeyedStream<Integer, String> keyDS = ds.keyBy(.....);
SingleOutputStreamOperator<Tuple2<String, Integer>> reduce = keyDS.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
//。。。。。。。。
return null;
}
});窗口
窗口一般是指一段时间范围,也就是时间窗口。窗口计算是指对这时间范围内的数据进行处理。
Flink为了更高效的处理无界数据流,一种方式是用窗口把无界数据流切割成多个有界数据流,然后进行分批处理。
在Flink中,窗口可以把无界数据流切割为多个数据桶,不同时间范围的数据流入到不同的桶中。当窗口时间结束后,就对这个桶中收集的数据进行计算处理。
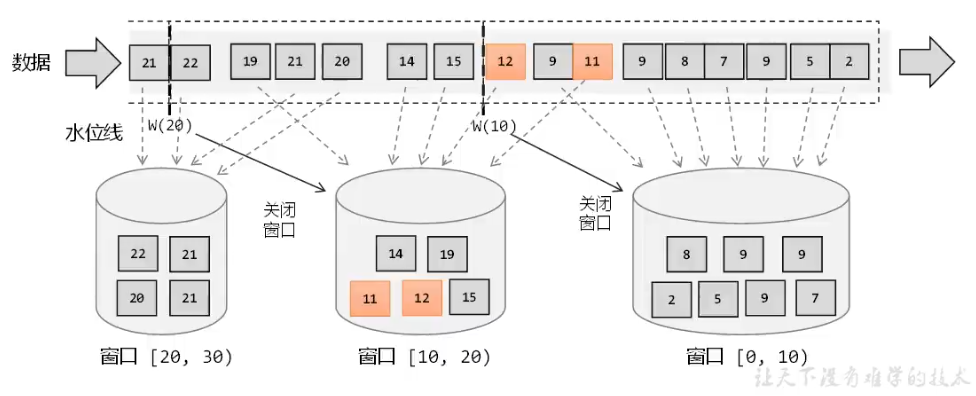
窗口分类
在Flink中,窗机有很多种类。
时间窗口
时间窗口以时间点来定义窗口的开始和结束。即时间窗口是某一时间段的数据。当时间窗口到达结束时间后,时间窗口不会再收集数据,开始触发计算并输出结果。最后将时间窗口销毁。
计数窗口
计数窗口是根据元素个数来截取数据流中的数据,当截取个数到达指定个数的时候,就会触发计算,并输出结果。最后计数窗口销毁。
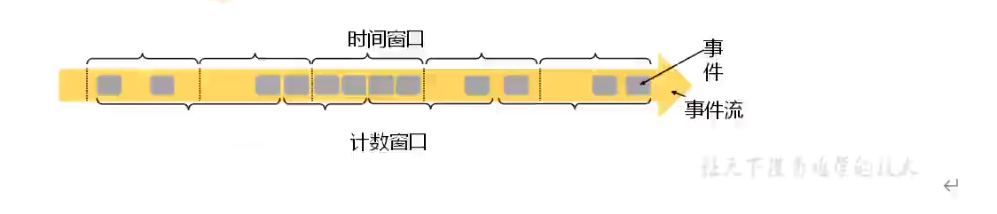
滚动窗口