[toc]
MySQL笔记15-底层
MySQL架构
MySQL架构图如下所示 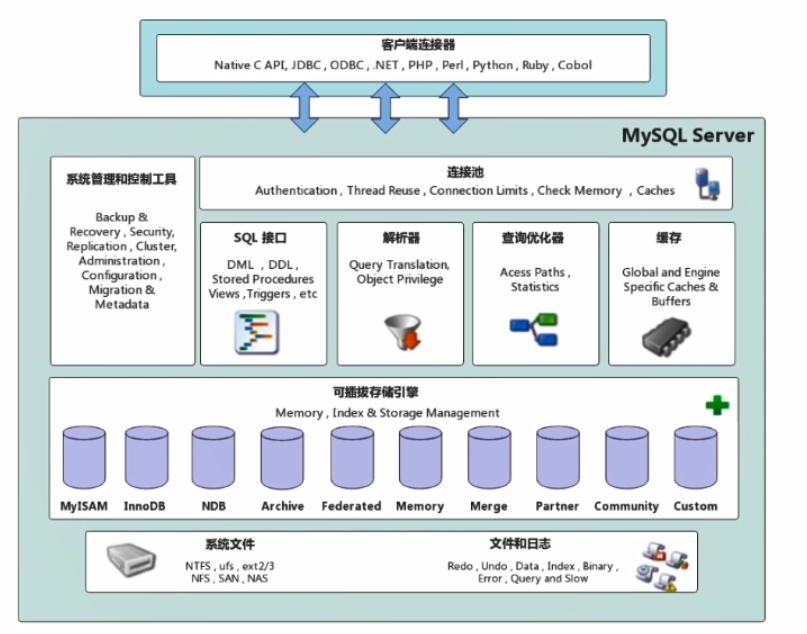
客户端连接器
客户端连接器负责与客户端进行通信。客户端连接器主要对接各个MySQL客户端。例如JDBC,navicat等。
连接池
连接池主要是存储和管理,客户端与服务端的数据库连接,一个数据库连接代表一个线程。。
当客户端与服务端建立好连接后,客户端就可以向服务端发送SQL语句了。
缓存
缓存会记录Mysql执行过的查询语句,以key-value键值对的方式存储在缓存中。key是查询语句,value是查询结果。
- 当Mysql服务端接收到客户端发过来的SQL语句后,如果是一个查询SQL语句,那么服务端会首先到缓存中查找是否存在过这个查询SQL语句。
- 如果SQL语句在缓存中,则直接从缓存中把查询结果返回给客户端。
- 如果SQL语句不在缓存中,则执行后面步骤。并将查询结果存入缓存中。
缓存的缺点:建议不要使用查询缓存,因为查询缓存的失效非常频繁
注意:MySQL 8.0版本直接将缓存的整块功能删掉了,标志着MySQL8.0开始彻底没有缓存这个功能了。
解析器
如果SQL语句没有命中查询缓存,那么服务端中的解析器会对客户端传来的SQL语句进行解析。
- 服务端中的解析器会对SQL语句进行解析。
- 解析器会对SQL语句进行解析。例如把关键字从SQL语句中提取出来。
- 解析器也会判断SQL语句是否出现语法错误。
如果解析器对SQL语句解析后,没有报错。此时SQL语句会进入优化器。
优化器
当解析器将SQL语句解析完成后,如果没有报错。说明SQL语句是符合语法并且可以执行的。此时解析器会把SQL语句传递给优化器。
优化器会对SQL语句进行优化。
若表有个组合索引(A,B,C)。当SQL语句是select ... where B=x and A=x and C=x。如果按照最左前缀原则,这个查询语句是不会触发组合索引的。但是优化器会把这个SQL语句优化为select ... where A=x and B=x and C=x。
当优化器将SQL语句优化完之后,会把优化后的SQL语句传递给执行器。
执行器
当执行器接收到优化器传递的SQL语句后,执行器会调用对应的存储引擎执行 SQL语句。主流的是MyISAM 和 Innodb 存储引擎。
存储引擎
存储引擎是真正执行SQL语句的。
物理文件存储层
物理存储层主要是将数据库的数据和日志存储在文件中,并与存储引擎打交道。
物理文件主要包括:数据文件,日志文件,配置文件,pid文件等。
数据文件是指:.ibd文件或.ibdata文件等,这些是存放数据或存放索引的文件。
日志文件是指:错误日志,bin日志等。
配置文件是指:存放MySQL所有的配置信息的文件,比如:my.cnf、my.ini等。
pid文件是指:进程文件,即mysql中的可执行文件等。
SQL语句中的关键字的执行方式
假如有三张表。分别是学生表,课程表,成绩表。
学生表(t_student)
| sid | sname | age | sex |
|---|---|---|---|
| 1 | 小明 | 12 | 男 |
| 2 | 小黑 | 13 | 男 |
| 3 | 小白 | 11 | 女 |
课程表(t_course)
| cid | cname |
|---|---|
| 1 | 语文 |
| 2 | 数学 |
| 3 | 英语 |
成绩表(t_score),sid为学生编号,cid为课程编号
| sid | cid | score |
|---|---|---|
| 1 | 1 | 55 |
| 1 | 2 | 67 |
| 1 | 3 | 86 |
| 2 | 1 | 66 |
| 2 | 2 | 78 |
| 2 | 3 | 87 |
group by 的执行方式
普通的group by语句
-- 根据sid字段值对t_score表的记录进行分组。
select * from t_score group by sid执行结果如下
| sid | cid | score |
|---|---|---|
| 1 | 1 | 55 |
| 2 | 1 | 66 |
执行流程:
- 先执行 from t_score 语句,得到临时表1
- 然后对 临时表1 执行 group by sid。即根据sid字段对临时表1进行分组。
- 先创建一个临时表2,然后全表读取临时表1的数据。
- 先读取临时表1的第一条行记录,有没有sid字段的值。如果有就把行记录加入到临时表2中。
- 继续读取临时表1的行记录。如果有与临时表2的sid字段不一样的值,才加入到临时表2中。否则不加入。
- 最终临时表2的数据才是SQL的结果集。
group by sid相当于针对sid字段进行数据去重。如果表中有多条sid相同的行记录,那么group by只会使用第一条行记录。因此效果相当于去重。
带有where的group by语句
-- 第一步:查询出score>60的t_score表的记录。形成临时表1
-- 第二步:根据sid字段值对临时表1的记录进行分组
select * from t_score where score > 60 group by sid注意:where 必须写在 group by 之前。并且 where 也是在 group by 之前执行的。
执行结果如下
| sid | cid | score |
|---|---|---|
| 1 | 2 | 67 |
| 2 | 1 | 66 |
执行流程:
- 先执行 from t_score where score > 60 语句,得到临时表1。
- 然后对 临时表1 执行 group by sid。即根据sid字段对临时表1进行分组。
- 先创建一个临时表2,然后全表读取临时表1的数据。
- 先读取临时表1的第一条行记录,有没有sid字段的值。如果有就把行记录加入到临时表2中。
- 继续读取临时表1的行记录。如果有与临时表2的sid字段不一样的值,才加入到临时表2中。否则不加入。
- 最终临时表2的数据才是SQL的结果集。
带有聚合函数的group by语句
-- 第一步:查询出t_score表的记录。形成临时表1
-- 第二步:根据sid字段值对临时表1的记录进行分组
-- 第三步:在分组的过程中,将相同的sid字段值的行记录的score字段值进行sum函数求和。
select sid,sum(score) from t_score group by sid执行结果如下
| sid | sum(score) |
|---|---|
| 1 | 208 |
| 2 | 231 |
执行流程:
- 先执行 from t_score 语句,得到临时表1。
- 然后对 临时表1 执行 group by sid。即根据sid字段对临时表1进行分组。
- 先创建一个临时表2,这个临时表2有sid和sum(score)两个字段。然后开始全表读取临时表1。
- 先读取临时表1的第一条行记录,有没有sid字段的值。如果有就把行记录加入到临时表2中。并将socre字段的值加入到sum(score)中。
- 继续读取临时表1的行记录。如果有与临时表2的sid字段一样的值,就将score字段值,加入到sum(score)中。如果有不一样的sid字段值,则把这条行记录加入到临时表2中。
- 依次类推
- 最终临时表2的数据才是SQL的结果集。
带有 HAVING 的group by语句
-- 第一步:查询出t_score表的记录。形成临时表1
-- 第二步:根据sid字段值对临时表1的记录进行分组
-- 第三步:在分组的过程中,将相同的sid字段值的行记录的score字段值进行sum函数求和。
-- 第四步:最后筛选出num字段大于210的记录
select sid,sum(score) as sum from t_score group by sid HAVING sum > 210执行结果如下
| sid | sum(score) |
|---|---|
| 2 | 231 |
执行流程:
- 先执行 from t_score 语句,得到临时表1。
- 然后对 临时表1 执行 group by sid。即根据sid字段对临时表1进行分组。
- 先创建一个临时表2,这个临时表2有sid和sum(score)两个字段。然后开始全表读取临时表1。
- 先读取临时表1的第一条行记录,有没有sid字段的值。如果有就把行记录加入到临时表2中。并将socre字段的值加入到sum(score)中。
- 继续读取临时表1的行记录。如果有与临时表2的sid字段一样的值,就将score字段值,加入到sum(score)中。如果有不一样的sid字段值,则把这条行记录加入到临时表2中。
- 依次类推
- 最后对临时表2的记录,筛选出num字段大于210的记录
注意:先执行 where ,后执行 group by ,最后执行 having。