[toc]
SqlAlchemy笔记1
SqlAlchemy
SQLAlchemy是一个基于Python实现的SQL工具包和ORM框架。
使用SQLAlchemy可以省去很多手动管理数据库连接、资源、事务等重复工作。让开发者更加高效地使用数据库。
许多大型Python项目都选择使用SQLAlchemy作为ORM框架。
SqlAlchemy的特点
- 支持Postgres、MySQL、Oracle等主流数据库。
- SQLAlchemy提供丰富的查询方式,如过滤、分组、联结等,可以构建复杂查询。
- 异步查询:基于Greenlet等实现异步查询,提高查询效率。
- 事务控制: 通过Session管理数据库会话和事务。
- 工具集成:如数据迁移工具Alembic,可以实现Schema版本控制和迁移。
- 大数据集查询:基于Pagination实现数据分页,避免大量数据查询内存溢出。
安装SqlAlchemy
SqlAlchemy本身需要数据库驱动才能进行数据库的操作。因此安装SqlAlchemy还需要安装相应的数据库驱动。
使用pip安装SqlAlchemy和pymysql数据库驱动
pip3 install sqlalchemy
pip3 install pymysql在python终端中查询SqlAlchemy的版本
# python终端
>>> import sqlalchemy
>>> sqlalchemy.__version__
'2.0.29'
>>>当前使用的SqlAlchemy版本为2.0.29
第一个 SqlAlchemy 例子
# 导入sqlalchemy
import sqlalchemy
# 创建数据库引擎
engine = sqlalchemy.create_engine("mysql+pymysql://root:123456@localhost:3306/my_test")
# 创建数据库连接对象
conn = engine.connect()
# 编写sql语句
query_sql = sqlalchemy.text("select * from t_student")
# 数据库连接对象执行sql语句
result_map = conn.execute(query_sql)
# 打印查询结果集
for row in result_map:
print(row)
# 关闭数据库连接对象
conn.close()
# 关闭数据库引擎
engine.dispose()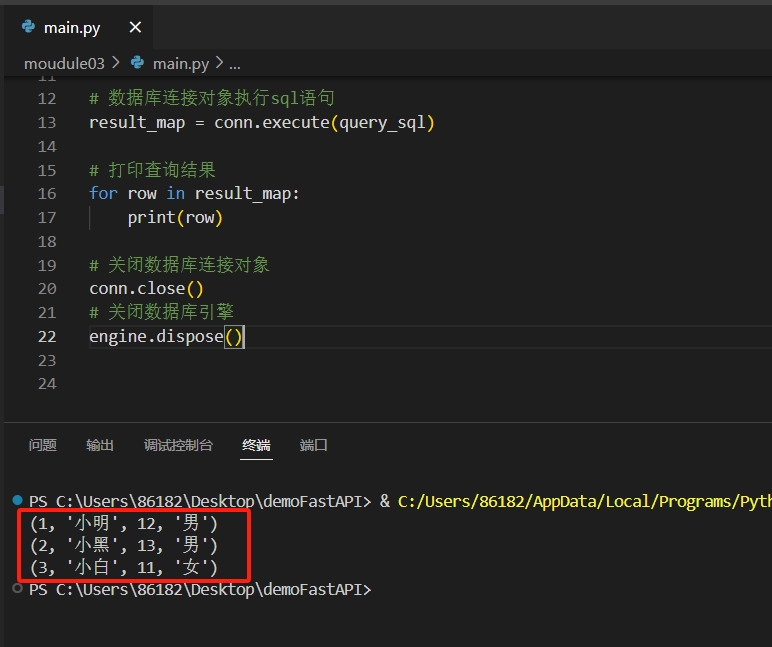
创建表
在SQLAlchemy中,有两种方式来创建表。
- 方式1:使用MetaData和Table对象直接定义表。
- 方式2:使用declarative_base创建一个基类,然后从这个基类派生自定义模型类,并使用Column和__table_args__定义表结构。
两种方式都需要在最后调用metadata.create_all(engine)或者Base.metadata.create_all(engine)来创建表。第一种方式更加面向对象,第二种方式更加直接。
注意:如果表已经存在,那么SQLAlchemy的这两种方式都不会去创建表。并且SQLAlchemy无法对已经存在的表进行表结构上的更新。需要通过其他方式来更新表结构。
方式1:使用MetaData和Table对象直接定义表。
# 导入sqlalchemy
import sqlalchemy
from sqlalchemy import Table,Column,Integer,String,Date
# 创建数据库引擎
engine = sqlalchemy.create_engine("mysql+pymysql://root:123456@localhost:3306/my_test",echo=True)
# 创建元数据
meta_data = sqlalchemy.MetaData()
# 定义表结构
school = Table(
"t_school",meta_data,
Column("id",Integer,primary_key=True),
Column("name",String(128),unique=True,nullable=True),
Column("address",String(128)),
Column("create_time",Date),
Column("update_time",Date)
)
# 调用元数据对象的create_all方法来创建表.
# 模型映射到数据库之中
meta_data.create_all(engine)执行这段代码后,sqlalchemy会自动连接数据库,并创建表。如果表已经存在,则不会创建。
方式2:使用declarative_base创建一个基类,然后从这个基类派生自定义模型类,并使用Column和__table_args__定义表结构。
# 导入sqlalchemy中的各个工具包
from sqlalchemy import create_engine, Column, Integer,String,DateTime,func
# 导入 declarative_base
from sqlalchemy.ext.declarative import declarative_base
# 导入 sessionmaker
from sqlalchemy.orm import sessionmaker
# 创建数据库引擎
engine = create_engine("mysql+pymysql://root:123456@localhost:3306/my_test",echo=True)
# 创建会话对象Session
Session = sessionmaker(engine)
db_session = Session()
# 创建基类
Base = declarative_base()
# 自定义的模型类TClass需要继承基类
class TClass(Base):
# 定义表名
__tablename__ = 't_class'
# 定义表字段
id = Column(Integer, primary_key=True,autoincrement=True,comment="id")
name = Column(String(50),unique=True, nullable=False,comment="班级名称")
address = Column(String(50),comment="班级地址")
remark = Column(String(50), default="", comment="备注")
created_time = Column(DateTime, server_default=func.now(), comment="创建时间")
updated_time = Column(DateTime, server_default=func.now(), onupdate=func.now(), comment="修改时间")
# 创建表
# 模型映射到数据库之中
Base.metadata.create_all(engine)- Base类 是用于定义 ORM 模型类的基类,提供了一些方便的功能。比如提供了一些CRUD的方法等。
- 自定义的模型类需要继承Base类。
primary_key=True是否是主键。unique=True是否是唯一值nullable=False是否为nullserver_default=func.now(), onupdate=func.now()创建或者修改的时候值为当前时间。
执行这段代码后,sqlalchemy会自动连接数据库,并创建表。如果表已经存在,则不会创建。
修改表
SQLAlchemy 不支持通过代码的形式直接修改表结构,但是可以执行原生的 SQL 来进行 ALTER TABLE 的操作。
增删改查
SQLAlchemy创建表的方式不同,那么增删改查数据的操作方式也不同。
下面是基于第二种创建表的方式(面向对象)的代码。第二种方式主要是通过会话对象Session来执行数据库语句操作。
插入数据
下面是插入数据的两种方式。
方式1:通过会话对象来直接插入数据
# 导入之前创建好的模型类和会话对象
from test03 import TClass,db_session
# 插入一条数据=======================
# 创建一个模型类对象作为插入的数据
one = TClass(name='jack',address="北京")
# 在db_session会话中添加对象
db_session.add(one)
# 提交会话
db_session.commit()
# 插入多条数据=======================
# 创建多个模型类对象
obj_list = [
TClass(name='tom',address="河南"),
TClass(name='bob',address="河南")
]
# 添加对象到session会话中
db_session.add_all(obj_list)
# 提交会话
db_session.commit()
# 关闭会话
db_session.close()方式2: 通过insert函数来先建insert sql语句,然后通过会话对象执行并提交 。
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test03 import TClass,db_session
from sqlalchemy import insert
# 插入一条记录=============
# 先创建insert语句
insert_sql = insert(TClass).values(name='xaxx', address='安徽')
# 打印insert语句
print(insert_sql)
# 通过会话对象执行insert语句
db_session.execute(insert_sql)
# 提交会话对象
db_session.commit()
# 关闭会话对象
db_session.close()
# 插入多条记录=============
# 通过insert方法创建sql语句。并被会话对象执行
db_session.execute(
insert(TClass).values([
{"name":'xxxss',"address":'安徽'},
{"name":'sdsdss',"address":'安徽2'}
])
)
# 提交会话对象
db_session.commit()
# 关闭会话对象
db_session.close()更新数据
下面是更新数据的两种方式。
方式1:通过会话对象来直接更新数据
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test03 import TClass,db_session
from sqlalchemy import insert
# 更新一条
# 先query查询出记录,然后update修改这条记录
res = db_session.query(TClass).filter(TClass.id == 2).update({'name': 'jack1'})
# 返回执行更新的的条数
print(res)
# 提交会话
db_session.commit()
# 关闭会话
db_session.close()方式2: 通过update函数来创建update sql语句,然后通过会话对象执行并提交 。
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test03 import TClass,db_session
from sqlalchemy import update
# 更新记录=============
# 先构建update语句
update_sql = update(TClass).where(TClass.id == 2).values(name='xasxx', address='安徽3')
# 打印语句
print(update_sql)
# 通过会话对象执行语句
db_session.execute(update_sql)
# 提交会话对象
db_session.commit()
# 关闭会话对象
db_session.close()删除数据
下面是删除数据的两种方式。
方式1:通过会话对象来直接删除数据
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test03 import TClass,db_session
# 删除一条记录
# 先查询出一条记录,然后delete()删除这条记录。
res = db_session.query(TClass).filter(TClass.id == 2).delete()
# 返回执行被删除的条数
print(res)
db_session.commit()
db_session.close()方式2:通过delete函数来创建update sql语句,然后通过会话对象执行并提交 。
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test03 import TClass,db_session
from sqlalchemy import delete
# 删除记录=============
# 先构建sql语句
delete_sql = delete(TClass).where(TClass.id == 2)
# 打印语句
print(delete_sql)
# 通过会话对象执行语句
db_session.execute(delete_sql)
# 提交会话对象
db_session.commit()
# 关闭会话对象
db_session.close()查询数据
普通查询
有两种方式来查询数据
方式1:
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test03 import TClass,db_session
# 1. 查询所有数据: all()
all_list = db_session.query(TClass).all()
# 遍历查询结果
print("查询所有数据:")
for item in all_list:
print(item.id,item.name,item.address)
# 2. 查询第一条记录
result = db_session.query(TClass).first()
print("查询第一条记录:")
print(result.id,result.name,result.address)
# 3. 带条件的查询
res = db_session.query(TClass).filter(TClass.id >= 2).all()
print("带条件的查询:")
for i in res:
print(i.id,i.name,i.address)
# 关闭会话对象
db_session.close()运行结构如图所示 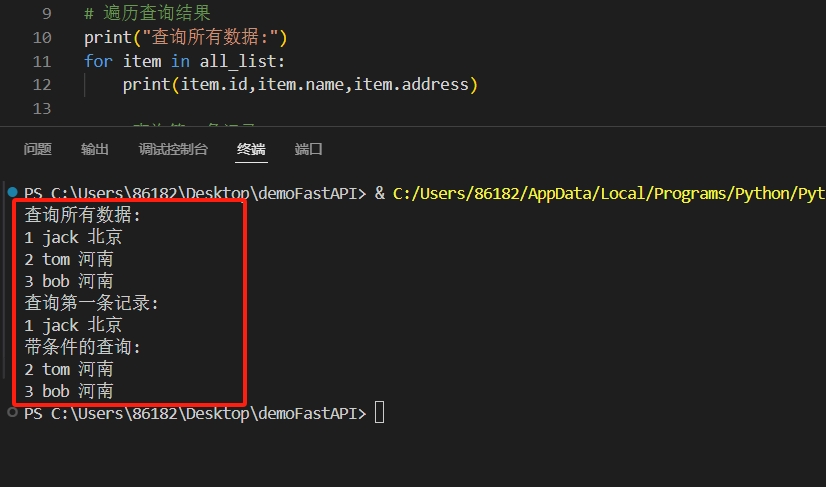
方式2:通过select函数来进行查询。
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test03 import TClass,db_session
from sqlalchemy import select
# 条件范围查询数据
select_sql = select(TClass).where(TClass.id >= 3)
print(select_sql)
result = db_session.execute(select_sql)
# 遍历查询结果
print("查询数据如下:")
for item in result:
print(item[0].id,item[0].name,item[0].address)
# 关闭会话对象
db_session.close()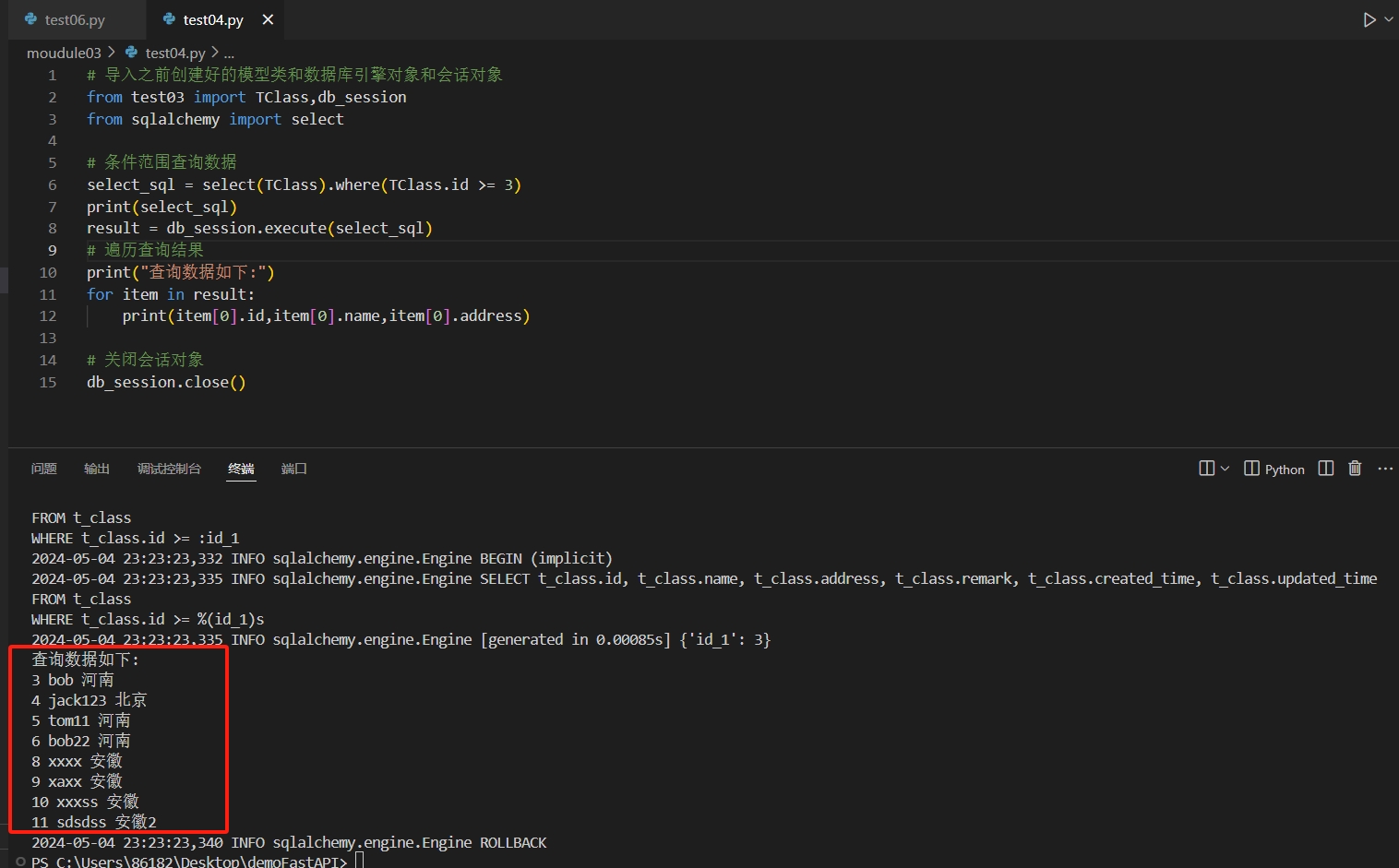
高级查询用法
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test03 import TClass,db_session
# 1. 查询所有数据: all()
all_list = db_session.query(TClass).all()
# 2. 查询第一条记录
result = db_session.query(TClass).first()
# 3. 带条件的范围查询
res = db_session.query(TClass).filter(TClass.id >= 2).all()
# 4. between查询,对于多个相同字段
res = db_session.query(TClass).filter(TClass.id >= 2, TClass.id <= 5).all()
# 5. and 查询,对于多个不同字段
res = db_session.query(TClass).filter(TClass.id == 2, TClass.name == 'jack').all()
# 6. or查询,使用or_()函数
res = db_session.query(TClass).filter(or_(TClass.id == 1, TClass.id == 3)).all()
# 7. order by 排序
# 根据id排序
res = db_session.query(TClass).order_by(TClass.id).all()
# 排序 : asc()
res = db_session.query(TClass).order_by(TClass.id.desc()).all()
# 8. in 查询。通过in_()函数
# id等于1,3,4的
res = db_session.query(TClass).filter(TClass.id.in_([1,3,4])).all()
# 9. not in 查询
# id不等于1,3,4的
res = db_session.query(TClass).filter(~TClass.id.in_([1,3,4])).all()
# 10. like模糊查询。like()函数
res = db_session.query(TClass).filter(TClass.name.like('a%')).all()
# 11. group by 分组查询
res = db_session.query(TClass).group_by(TClass.id).all()
# 关闭会话对象
db_session.close()多表关联查询数据
inner join查询的语法如下
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test03 import TClass,db_session
# 语法如下。这是2个表的inner join关联查询。
db_session.query(左表.字段,右表.字段)
.join(右表, 关联条件).all()
# 例子
result = db_session.query(ModuleA,ModuleB)
.join(ModuleB,ModuleA.id == ModuleB.id).all()
# 查询结果是元组数组
# 例如下面就是一个元素数组
[({"xxx": "xxxx", "111": 1}), ({"xxx": "xxxx", "111": 1}), ({"xxx": "xxxx", "111": 1})]left join查询的语法如下
LEFT JOIN只需要在每个JOIN中指定isouter关键字参数为True即可
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test03 import TClass,db_session
# 语法如下。这是2个表的left join查询
db_session.query(左表.字段,右表.字段)
.join(右表,关联条件,isouter=True).all()
# 例子
result = db_session.query(ModuleA,ModuleB)
.join(ModuleB,ModuleA.id == ModuleB.id,isouter=True).all()right join查询的语法如下
RIGHT JOIN需要换关联表的位置即可。注意 SQLALchemy 本身并未提供RIGHT JOIN
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test03 import TClass,db_session
# 语法如下。这是2个表的right join查询
db_session.query(左表.字段,右表.字段)
.join(左表,关联条件,isouter=True).all()
# 例子
result = db_session.query(ModuleA,ModuleB)
.join(ModuleA,ModuleA.id == ModuleB.id,isouter=True).all()具体例子
- 创建两个表。部门表和员工表
# 导入sqlalchemy中的各个工具包
from sqlalchemy import create_engine, Column, Integer,String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# 根据数据库引擎创建session会话对象
Session = sessionmaker(engine)
db_session = Session()
# 创建数据库引擎
engine = create_engine("mysql+pymysql://root:123456@localhost:3306/my_test",echo=True)
# 创建基类
Base = declarative_base()
# 部门模型类
class Dept(Base):
# 定义表名
__tablename__ = 't_dept'
# 定义字段
id = Column(Integer,primary_key=True,autoincrement=True,comment="部门编号")
name = Column(String(50),unique=True, nullable=False,comment="部门名称")
# 员工模型类
class Employee(Base):
# 定义表名
__tablename__ = 't_employee'
# 定义字段
id = Column(Integer,primary_key=True,autoincrement=True,comment="员工编号")
dept_id = Column(Integer,comment="部门编号")
name = Column(String(50),unique=True, nullable=False,comment="员工名称")
# 创建数据库表
Base.metadata.create_all(engine)- 进行关联查询
# 导入之前创建好的模型类和数据库引擎对象和会话对象
from test05 import Dept,Employee,db_session
# 关联查询
result = db_session.query(Employee,Dept).join(Dept,Employee.dept_id == Dept.id,isouter=True).filter(Dept.id == 2).all()
# 打印查询结果
for i in result:
print(i[0].id,i[0].name,i[1].id,i[1].name)
# 关闭会话
db_session.close()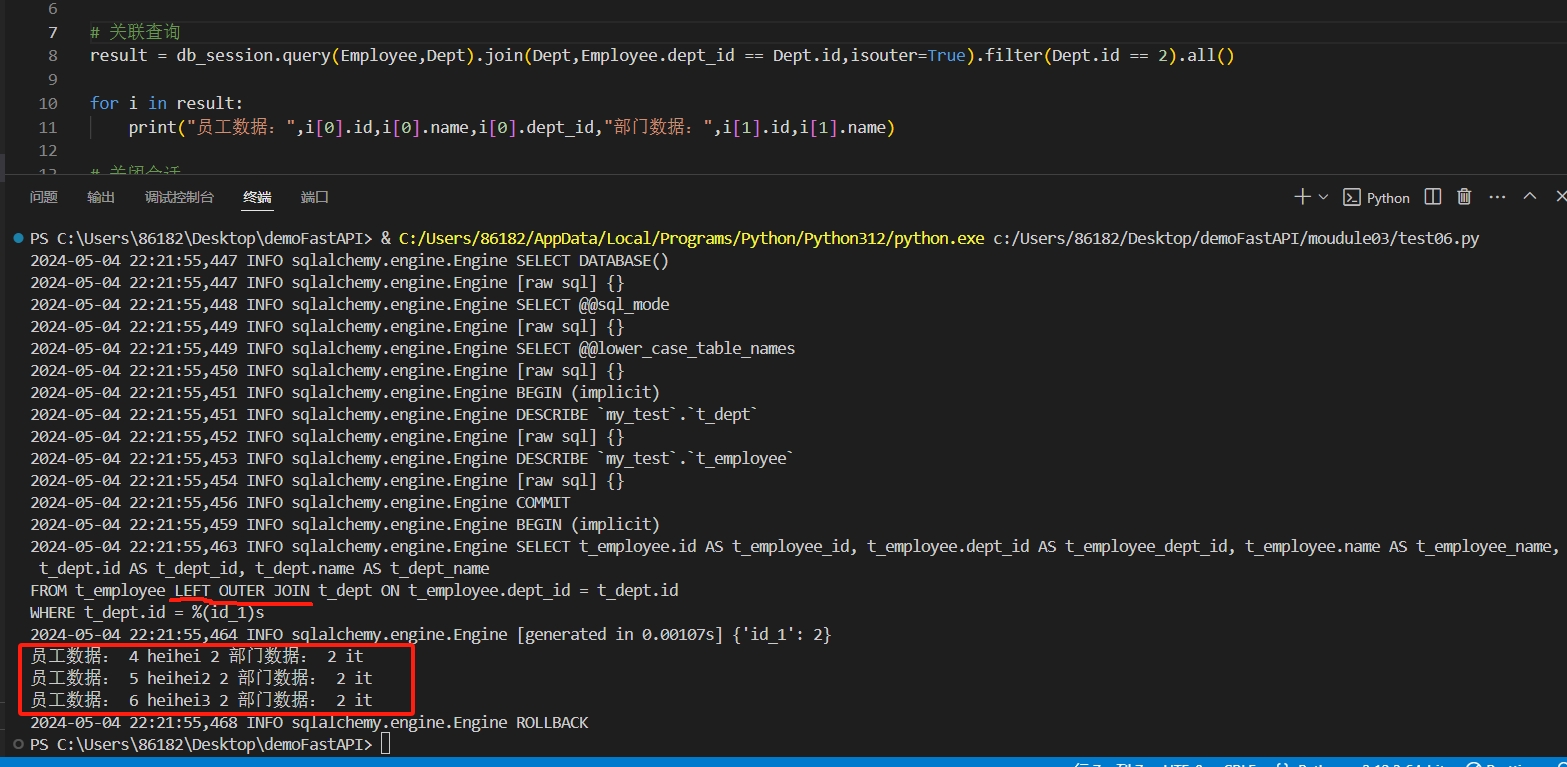
sqlalchemy-serializer 序列化工具库
sqlalchemy-serializer 是一个专为 SQLAlchemy ORM 设计的序列化工具库,它提供了简单而强大的方式将 SQLAlchemy 模型对象转换为可序列化的字典数据或 JSON 数据。
安装 sqlalchemy-serializer 库
pip install sqlalchemy-serializer使用方式
如果想要某个sqlalchemy模型类能够被序列化,那么需要在定义sqlalchemy模型类的适合,让该模型类继承sqlalchemy_serializer.SerializerMixin类即可。
SerializerMixin类会给sqlalchemy模型类提供一个to_dict方法,该方法可以将sqlalchemy模型类对象转换为一个字典数据。
示例如下
from sqlalchemy import Column, Integer, String ,DateTime,CHAR,func
# 导入sqlalchemy_serializer库的SerializerMixin类
from sqlalchemy_serializer import SerializerMixin
# 定义sqlalchemy模型类,并继承SerializerMixin类
class UserModel(db.Model, SerializerMixin):
__tablename__ = "t_user"
id = Column("id",Integer, primary_key=True, autoincrement=True, comment='id')
name = Column("name",String(255),unique=True,nullable=False, comment='名称')
password = Column("password",String(255),unique=True,nullable=False, comment='密码')
# 查询用户,返回单个sqlalchemy模型类对象
user = db_session.query(UserModel).filter(UserModel.id == 111).first()
# 调用to_dict方法将sqlalchemy模型类对象转换为字典数据
user_dict = user.to_dict()
# 打印序列化后的字典数据
print(user_dict)
# 查询用户列表,返回sqlalchemy模型类对象数组
user_list_items = db_session.query(UserModel).all()
# 调用to_dict方法将sqlalchemy模型类对象数组转换为字典数据数组
user_dict_list = [item.to_dict() for item in user_list_items]
# 打印序列化后的用户列表
print(user_dict_list)排除某个序列化字段
如果sqlalchemy模型类中的有的字段不需要被序列化,比如密码字段,那么可以通过设置rules参数,或者only参数来指定序列化规则。
代码示例如下
# 查询用户,返回单个sqlalchemy模型类对象
user = UserModel.query.filter(...).one()
# 调用to_dict方法将sqlalchemy模型类对象转换为字典数据,排除password字段
user_dict = user.to_dict(rules=('-password',))
# 调用to_dict方法将sqlalchemy模型类对象转换为字典数据,排除password和name字段
user_dict = user.to_dict(rules=('-password','-name'))- 调用to_dict方法的时候,传递了rules参数,并且设置了
-password,其中的-号代表排除的意思,意思是不要序列化password字段。
排除多个序列化字段
我们还可以在SqlAlchemy模型类中定义一个__serializer_rules__属性,该属性的值是一个元组,元组中包含了需要被排除的字段名。
代码示例如下
# 定义sqlalchemy模型类,并继承SerializerMixin类
class UserModel(db.Model, SerializerMixin):
__tablename__ = "t_user"
id = Column("id",Integer, primary_key=True, autoincrement=True, comment='id')
name = Column("name",String(255),unique=True,nullable=False, comment='名称')
password = Column("password",String(255),unique=True,nullable=False, comment='密码')
# 定义需要被排除的字段名
__serializer_rules__ = ('-password','-name')
# 查询数据
user = db_session.query(UserModel).filter(UserModel.id == 111).first()
# 此时调用to_dict方法进行序列化数据,会自动排除__serializer_rules__属性中定义的字段
user_dict = user.to_dict()
print(user_dict)